In this article I'll walk you through modeling Social Library, a social app for
book enthusiasts, using GunDB. This fictitious app helps readers create favorite
lists from the books they like, leave reviews and follow other readers and
authors. I'll start by talking about what data modeling is and then I'll walk
you through creating a graph data model for the app. Then, I'll implement the
entities and relationships with GunDB, and finally I'll create some fake data
and show you how to run some queries against the data. If you just want to read
the GunDB-related portion, you can skip to the "Designing for GunDB" section. If
you are new to GunDB you may want to check out my other article on the basics of GunDB.
All the code snippets for this article are available on Gitlab.
Disclaimer
The code examples and models introduced in this article are for demonstration
purposes only and may not be accurate for the business domain discussed. In
addition, the models presented do not cover all the use cases mentioned in the
article. However, there are enough examples introduced so that you can design
your own model or expand and improve the ones discussed.
Introduction
Generally speaking, data modeling is a design process in which you identify the
entities in a system, describe their attributes and the relationships between
the entities. The end result is ideally a database-agnostic document, with
diagrams, that documents the results. It's also important for the document to be
maintainable through the project development, either in code using version
control, or using diagramming tools.
But how would you start the modeling process? You can start by gathering as much
information as possible. You talk to the people who know the most about the
business needs and identify the use cases. Use cases can reveal a lot about a
system and can guide the design process very effectively. In addition, use cases
directly correspond to features, or so-called vertical slices, that software
teams can then turn into deliverables.
After use cases have been documented, the next step is to extract the entities,
their attributes, and the relationships. This usually involves listing out the
entities, their properties and drawing some diagrams describing the
relationships. The final result is a maintainable document that everyone can
refer to and update throughout the development life-cycle of a project.
After the first version of the document has been finalized, then you move onto
adding design requirements specific to the database system that you are going to
use. For relational databases for example, it would involve identifying tables,
foreign keys, join tables, schemas, and so on. For document-based databases, for
example it would involve identifying documents, references, and maybe some
schemas.
Now, for graph databases, regardless of the database, you are almost always
going to decide on the following three components:
- Nodes: the entities of a system
- Node properties: the attributes of each entity
- Edges: the relationships between the entities
Modeling the Social Library App
In the following sections we are going to go through the design process of the
Social Library app. We will identify some of the entities, their attributes, and
their relationships. We will extend the design for GunDB and finally create some
fake data and explore running queries. Please note that some features of the app
might be left out in the data model. But we will cover enough entities and
relationships so that you can have a good starting point if you were interested
in designing the model for the entire app.
Use Cases
Below are the use cases that we have identified after gathering information
about the app:
Users
- A user can be a reader, author, publisher, or a combination of all three.
- The app will have readers and authors that can create accounts
- Readers and authors can have profiles that they can use to share a little about themselves.
- Admins can perform administrative tasks, like creating books or managing publishers in the system.
- Publishers can manage the books that they have published
Readers
- Readers can favorite books. They can create lists and add books to their lists. A book can be in multiple lists depending on what the reader chooses. They can also decide which list should stay private and which ones public.
- Readers can review books. They can rate a book from 1 to 5 and leave a review about it. They can submit reviews and have the reviews show up when visiting a book's details page.
- Readers can follow other readers. You can go to a reader's profile and see their followers and also the readers they follow.
- Readers can also follow authors. Similar to the use case above, you can see the authors they are following, and the authors that follow them.
Feed
- The idea is that anyone who uses the app, including anonymous users, can see the latest updates. For example, they can see the new books that have been added or the most popular books of the month and so on.
Books
- Admins can add books and manage existing ones.
- Books should be easily searchable through categories or keywords
- Books should be added in a way that recommendations can be given to readers depending on what books they have liked or read.
Identifying Entities, Relationships, and Queries
Now it's time to identify the entities, their attributes, and the relationships.
From the use cases above, we are going to focus on the following:
Entities
Below are some of the entities of the system that we are going to focus on:
- User
- Reader
- Author
- Publisher
- Book
- Book Category
Attributes
Here are the attributes for the entities mentioned above:
User
- name
- username
- roles
Reader:
- name
- favorite books
- reviews
- following
- followers
Author:
- name
- books
- followers
- following
Book:
- title
- subtitle?
- isbn
- authors
- publisher
- categories
- reviews?
Book Category:
- name
Relationships
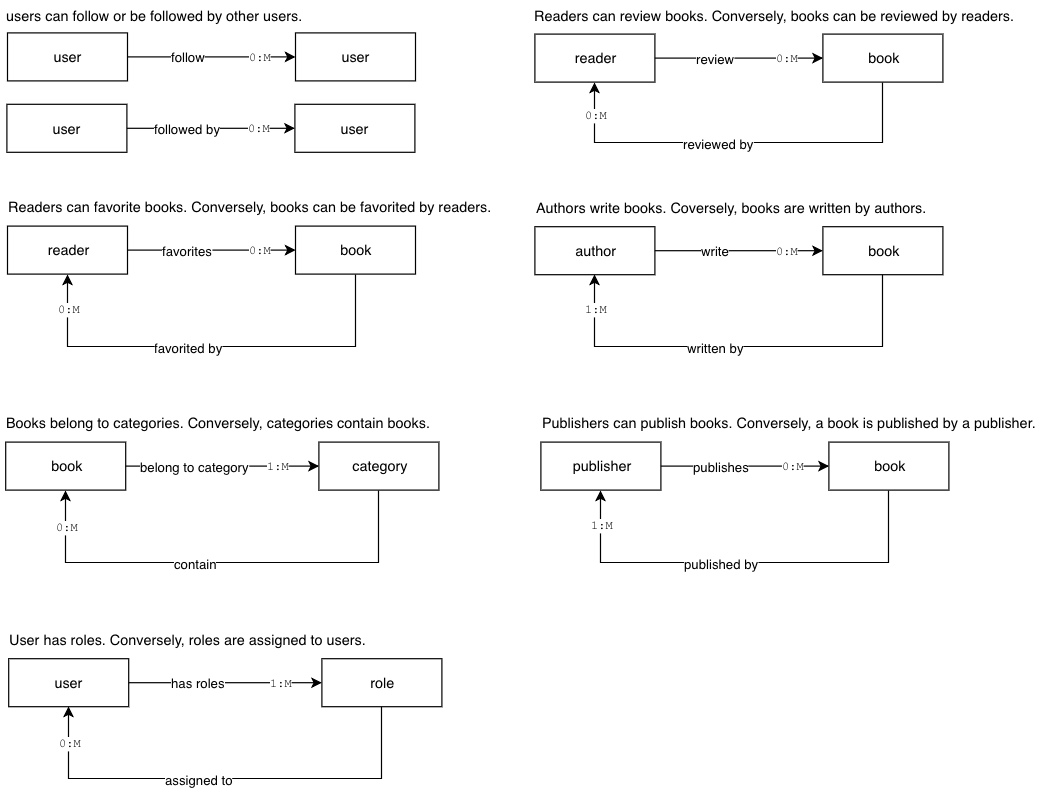
Below are some the relationships between the entities mentioned above:
- A user can be a reader, author, publisher, or a combination of three roles
- Users can follow 0 to many users
- Readers can review 0 to many books
- Readers can favorite 0 to many books
- Books belong to 1 or many categories
- Authors can author 0 to many books
- Publishers publish 0 to many books
The figure below summarizes the above relationships:
Identifying Queries
In this section, we are going to think about how we are going to use the data.
In other words, we're going to think about the queries that we want to run
against the data. Identifying queries is instrumental in designing a good model
that can help us answer questions about the data. Below is a summary of how we
want to use the data and the queries that we want to run. Notice that here we
are mostly focusing on the relationships between the entities and some holistic
insights about the data:
Given a reader:
- get their reviews
- get their followers (authors or other readers)
- get who they are following
- get their private and public favorite lists of books
Given an author:
- get the books they have written
- get their followers (readers or other authors)
- get who they are following
Given a book:
- get the categories it belongs to
- get its reviews
- get its authors
- get its publisher
- get the readers who have favorited it
- get the authors that have authored or co-authored it
Given a publisher
- get the books they have published
- get the authors who have worked with a publisher
Given a book category:
- get the books that belong to the category
- given a book, get all the categories it belongs to
In addition to the above queries, we also want to be able to answer the
following questions:
- What are the most popular books? A popular book can be defined as a book that has the most 5 star reviews and has the largest number of readers adding them to their favorite lists
- What titles, keywords, or categories that have been searched the most?
- Given a rating value, what are the books with that rating? For example, we want to be able to see all the books with a rating of 2
- What are the books that two or more readers like in common? This assumes only the public favorites lists shared by the readers
- Given two or more readers/authors, who are the followers/followings they have in common?
- Given a keyword, return all the books that have the search keyword
Designing for GunDB
In this section we are going to use the information from the previous sections
and create a graph model to be specifically implemented for GunDB.
Nodes and Properties
First, let's start by talking about the nodes representing the entities, and
define their properties:
Book
book
- uuid: string (internal)
- type: string (internal)
- title: string
- subtitle: string
- isbn: string
--
* reviews: Set
* categories: Set
* authors: Set
* publisher: Link
Tip: if you use draw.io for creating diagrams, you can automatically create a
diagram from the definition above. See Appendix 1 for more details.
Book Category
book_category
- uuid: string (internal)
- type: string (internal)
- name: string
--
* books: Set
I'm using an asterisk*to specify a property which is a pointer or link to
another node or set
User
user
- uuid: string (internal)
- type: string (internal)
- name: string
- username: string
- email: string
--
* roles: Set
Reader
reader
- uuid: string (internal)
- type: string (internal)
- name: string
--
* book_reviews: Set
* following: Set
* followers: Set
* favorite_books: Set
Author
author
- uuid: string (internal)
- type: string (internal)
- name: string
--
* books: Set
* following: Set
* followers: Set
Publisher
publisher
- uuid: string (internal)
- type: string (internal)
- name: string
- address: string
--
* books: Set
* authors: Set
The figure below summarizes all the node descriptions defined above:

Relationships
In this section, we are going to explore representing relationships with GunDB.
GunDB by default creates relationships in one direction and doesn't force you to
define properties for edges. It gives you the freedom to decide which edges need
properties and which entities need bi-directional relationships. You have
complete control when it comes to designing the graph model of your system.
However, it's useful to use link nodes to describe properties for relationships.
Review Book:
Reviewing a book can be represented by a link node between a reader and a book
with the following properties:
review_book (Link Node)
- uuid: string (internal)
- type: string (internal)
- name: string (internal)
- rating: number (integer, 1 <= n < 6)
- content: string (max 375 characters)
--
* book: Node
* reader: Node
This link node has some properties including the rating value and the content of
the review. It also includes two references, one to the book, and the other to
the reader. Below is a diagram describing how an "instance" of a review_book
would look like in relation to a book and a reader:
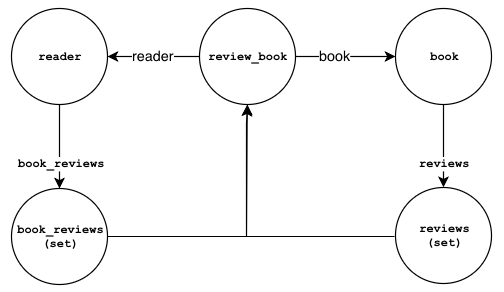
There are a couple of things worth mentioning about the diagram above:
- We have made all the links bi-directional on purpose so we can traverse the links from any given node
- From a
review_booklink node, we can either get to the reader or to the book - From a
readerwe can get to their reviews from thebook_reviewsset - From a
bookwe can get to the reviews from thereviewsset
We can also describe the relationships above as plain text:
;Review Book:
reader->book_reviews->book_reviews(set)
book_reviews(set)->review_book
review_book->reader->reader
review_book->book->book
book->reviews->reviews(set)
reviews(set)->review_book
Tip: you can use Draw.io to automatically create a diagram from the graph
definition above. See Appendix 1 for more details.
The rest of the relationships that we are going to explore are very similar, in
terms of structure, to the one discussed above. That is, the starting or end
nodes will have a set that point to relationship links. And the node link
themselves will have one reference to the "source", and another to the
"destination" node.
Author Book
Authoring a book can be represented by a link node between an author and a book
with the following properties:
author_book (Link Node)
- uuid: string (internal)
- type: string (internal)
- name: string (internal)
- date: string (ISO date)
--
* book: Node
* author: Node
The relationships between an author and the books are show below:
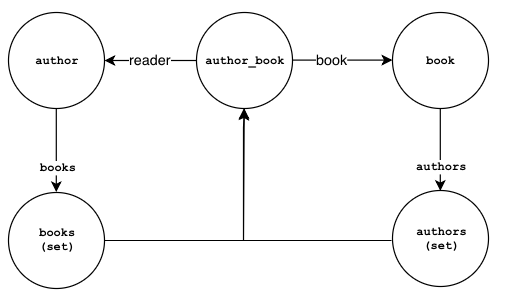
;Author Book:
author->books->books(set)
books(set)->author_book
author_book->author->author
author_book->book->book
book->authors->authors(set)
authors(set)->author_book
Favorite Books
A favorite book list can be represented by a node between a reader and a book
with the following properties:
favorite_list (Link Node)
- uuid: string (internal)
- type: string (internal)
- name: string (internal)
- list_name: string
- is_public: string ("true" or "false")
--
* books: Set
* belongs_to: Node
The nodes and the relationships are shown in the diagram below:
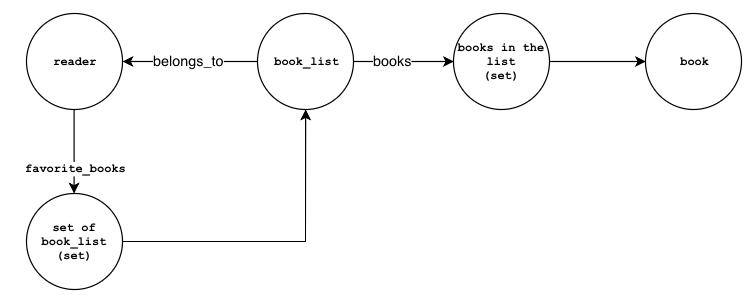
;Reader's favorite books:
reader->favorite_books->favorite_books(set)
favorite_books(set)->book_list
book_list->books->books(set)
book_list->belongs_to->reader
books(set)->book
Book Category
A book category relationship can be represented by a link node between a book
and a category node:
book_category (Link Node)
- uuid: string (internal)
- type: string (internal)
- name: string (internal)
- category_name: string
--
* book: Node
* belongs_to: Node
The nodes and the relationships are show in the diagram below:
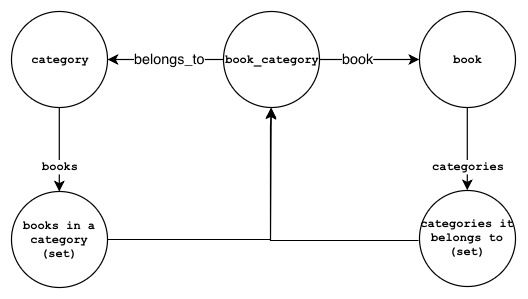
;Books in a category:
category->books->books(set)
books(set)->book_category
book_category->belongs_to->category
book_category->book->book
book->categories->categories(set)
categories(set)->book_category
Publish Book
Publishing a book can be represented by a link node between a publisher and a
book:
publish_book (Link Node)
- uuid: string (internal)
- type: string (internal)
- name: string (internal)
- date: string (ISO date)
--
* book: Node
* publisher: Node
The relationships between a book and its publisher is shown below:
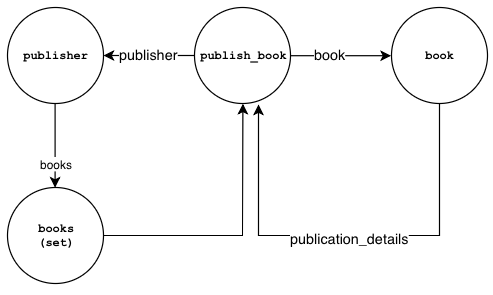
;Publish Book:
publisher->books->books(set)
books(set)->publish_book
publish_book->publisher->publisher
publish_book->book->book
book->publication_details->publish_book
User Roles
A user's role can be represented by a link node between a user node and a user
type like a reader, author, or publisher:
role (Link Node)
- uuid: string (internal)
- type: string (internal)
- name: string (internal)
- role_name: string
--
* role_type: Node
* user: Node
* permissions: Set
The diagram below shows how the relationships would look like:
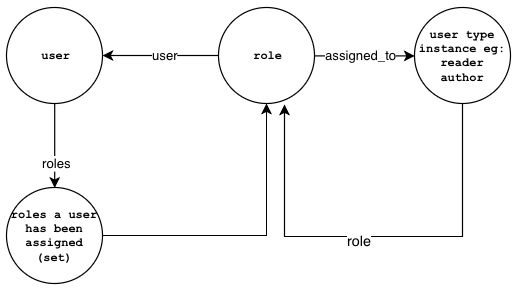
;User Roles:
user->roles->roles(set)
roles(set)->role
role->assigned_to->user_type
role->user->user
user_type->role->role
roles/name->role
Follow Readers/Authors
Following a reader or an author can be represented by a link node between the
two:
follow (Link Node)
- uuid: string (internal)
- type: string (internal)
- name: string (internal)
- date: string (ISO date)
--
* reader: Node
* by_reader: Node
The diagram below, describes the relationship between one reader following
another reader:
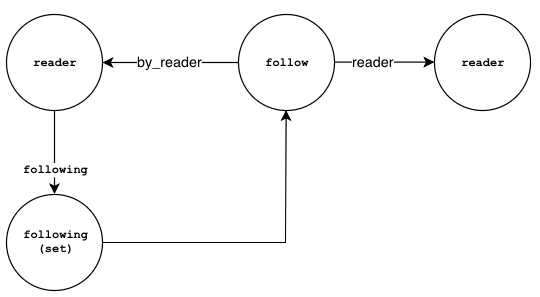
Note that a similar relationship can be defined for readers following authors or
authors following readers or other authors. You can still keep the relationship
name as "follow", but then you would probably want to rename the link properties
to a more appropriate names. For example, the relationship between an author
following a reader can be defined as:
follow (Link Node)
- uuid: string (internal)
- type: string (internal)
- name: string (internal)
- date: string (ISO date)
--
* reader: Node
* by_author: Node
Another possibility is to generalize the "follow" relationship from one user to
another user and not worry about the type of the user. In that case, the
relationship can be defined as:
follow (Link Node)
- uuid: string (internal)
- type: string (internal)
- name: string (internal)
- date: string (ISO date)
--
* user: Node
* by_user: Node
In this case, as long as users and user types are linked properly, you can
traverse the graph from any node and find their followers, and who they are
following. We will explore this more when creating the graph with GunDB in the
next section.
Creating the Graph
Now that we have defined the nodes, their properties, and the relationships,
it's time to add some fake data and test the model. The goal here is to create a
graph with GunDB, using the definitions above, and run some queries against the
data to verify we get the correct data back.
Adding Fake Data
First, let's start by creating some fake books:
function fakeBooks(opts = {n: 5}) {
const books = [];
let howMany = opts.n;
while(howMany-- > 0) {
let id = uuid();
let count = (opts.n - howMany);
const book = {
uuid: id,
type: "Book",
title: `The Book Title ${count}`,
subtitle: `Lorem ipsum dolor ${count}`,
isbn: count,
};
books.push(book);
}
return books;
}
The function above, by default, returns an array of five plain JavaScript objects
representing books. Next, we want to call this function and create Gun nodes
from the book objects:
const db = Gun();
const books = fakeBooks();
for (let b of books) {
db.get(b.uuid).put(b);
}
For convenience, we are also going to create a JavaScript array that holds
references to the Gun nodes that we just created:
const bookNodes = books.map(b => db.get(b.uuid));
We can repeat the same steps for creating fake data for the other entities. The
rest of the functions for generating fake data are all
included in the article's repository on Gitlab.
Adding Relationships
Review Book
Now, that we have some fake data, let's go through creating the relationships.
The first relationship that we are going to look at is book reviews. The diagram
below illustrates the nodes and the links that we are going to need to create:
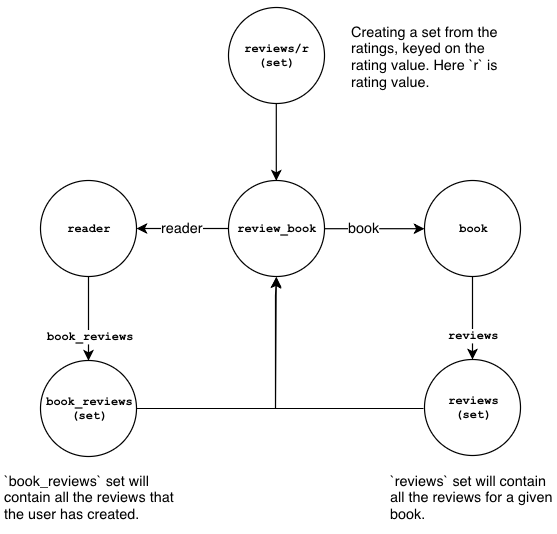
- The
review_booklink node represents a reader reviewing a book. - The
bookproperty inreview_bookreferences the book being reviewed. - The
readerproperty inreivew_bookreferences the reader creating the review. - The
reviews/rset holds references toreview_booknodes, grouped by rating. - The
book_reviewsproperty in thereadernode is a set that holds references toreview_booknodes. - The
reviewsproperty in thebooknode is a set that holds references toreview_booknodes.
Now, we can define a function that creates the nodes and the links shown above:
function reviewBook(opt) {
const {db, reader, book, rating, content} = opt;
const linkId = uuid();
const review = db.get(linkId).put({ // A
uuid: linkId,
type: "Link",
name: "review_book",
rating: rating,
content: content,
});
review.get("book").put(book); // B
review.get("reader").put(reader); // C
db.get(`reviews/${rating}`).set(review); // D
book.get("reviews").set(review); // E
reader.get("book_reviews").set(review); // F
return review;
}
In the snippet above, the reviewBook function accepts an object that holds the
following references:
- a db instance
- a reader node
- a book node
- rating value for the review
- content for the review
Then, we create a review_book link node on line A, setting the rating and
content using the passed in values. On line B, we create a property on the
review called book that points to the given book node. On line C, we define a
property called reader that points to the given reader node. On line D, we add
the review node to the review/rating set. This set will help us reference
reviews by rating values. On line E, we create a set on the given book node
called reviews and we add the review node to it. On line F, we create a set on
the reader node called book_reviews and we add the review node to it. And
finally we return the review_book link node from the function.
Now that we have this function, in the main file we can create reviews by
readers. For example, we can create two reviews by Reader 1:
reviewBook({
db,
reader: readerNodes[0],
book: bookNodes[0],
rating: 5,
content: "Great book!",
});
reviewBook({
db,
reader: readerNodes[0],
book: bookNodes[1],
rating: 1,
content: "It was ok.",
});
To quickly test the book review relationships we can run the following queries
and manually verify the results:
- Log all the reviews by Reader 1
readerNodes[0].get("book_reviews").map().once(console.log);
- Log all the book titles reviewed by Reader 1:
readerNodes[0].get("book_reviews").map().get("book").get("title").once(console.log);
- Given Book 1, log its reviews:
bookNodes[0].get("reviews").map().once(console.log);
- Given Book 1, log the 5-star reviews:
bookNodes[0].get("reviews")
.map()
.once(review => {
if(review.rating === 5) {
db.get(review.book).once(b => {
console.log(review);
});
}
});
- Given Book 1, log the names of the readers who reviewed the book:
bookNodes[0].get("reviews").map().get("reader").get("name").once(console.log);
- Log all the one-star reviews:
db.get("reviews/1").map().once(console.log);
- Given the one-star reviews, log the book titles:
db.get("reviews/1").map().get("book").get("title").once(console.log);
- Given the one-star reviews, log the readers who left the reviews:
db.get("reviews/1").map().get("reader").get("name").once(console.log);
All the queries above execute just fine, but I noticed duplicate results (when
the number of entries increase) after I run queries like the one below:
readerNodes[0].get("book_reviews").map().get("book").once(log);
And to get around I do the following instead:
readerNodes[0].get("book_reviews").map().once(v => db.get(v.book).once(log));
Now I'm not sure why that's happening. Either I'm not using chaining properly,
or there might be other assumptions about queries that I'm not aware of. One
thing however that's confusing to me is that when I expand to a property name,
instead of a node, I don't get duplicate results:
readerNodes[0].get("book_reviews").map().get("book").get("title").once(console.log);
In the snippet above, instead of logging the book nodes, I'm logging the title
of the books and that works just fine.
Queries Using Promises
GunDB uses a streaming API which is perfect for real-time apps. But there might
be situations where you want to use promises to get a set of results once and
not listen for updates. GunDB includes an extension that enables you to turn a
query into a promise. In this section we are going to turn some of the queries
above to promises using the then extension.
First, we need to include the then extension. If you use npm to install Gun,
the then extension is included in node_modules/gun/lib/then. You can load it
after including Gun:
const gun = require("gun");
require("gun/lib/then");
After the extension is included, the Gun chain includes the then method that
you can use to turn a chain into a promise. For example, the following snippet
return a promise that resolves to a map that contains the keys and the meta data
for each key:
const result = readerNodes[0].get("book_reviews").then();
Now, to extract the data, you can do something like this:
const removeMetaData = (o) => { // A
const copy = {...o};
delete copy._;
return copy;
};
const bookReviews = readerNodes[0].get("book_reviews").then() // B
.then(o => removeMetaData(o)) // C
.then(refs => Promise.all(Object.keys(refs).map(k => db.get(k).then()))) // D
.then(r => console.log(r)); // E
- On line A we define a helper function to create a copy of an object and remove the "_" meta data field.
- On line B, we run a get query on book reviews created by a reader and start the chain promise.
- On line C, we use our helper function to remove the meta data and return a copy that only includes result keys.
- On line D, we take the references and we use
db.getto resolve them to data nodes. Here is the break-down of each step for line D:
Line D
-
Object.keys(refs): returns a JavaScript array containing the the Gun keys/references -
.map(k => db.get(k).then()): returns a JavaScript array containing the result ofdb.get.thenfor each key. The result is an array of promises. -
Promise.alltakes the array of promises and resolves them to nodes. - And finally on line E we log the data nodes.
Here is another query using promises:
- Log all the one-star rated books:
db.get("reviews/1").then()
.then(filterMetadata)
.then(r => Promise.all(Object.keys(r).map(k => db.get(k).then())))
.then(r => Promise.all(Object.keys(r).map(k => db.get(r[k].book["#"]).then())))
.then(r => log(r));
The article's repository includes a query helper that simplyfies the queries
above. You can see some examples in the
query_test.js
file.
Author Book
The next relationship that we are going to look at is authoring books. The
diagram below illustrates the links and the nodes that we are going to create:
- The
author_booklink node represents authoring a book by one or more authors. - The
bookproperty in theauthor_booknode references the authored book. - The
authorproperty in theauthor_booknode references an author of the book. - The
bookproperty in theauthornode references a set that holds references toauthor_booknodes. - The
authorsproperty in thebooknode references a set that holds references toauthor_booknodes.
Now, we can define a function that creates the nodes and the links shown above:
function authorBook(opt) {
const {db, author, book, date} = opt;
const linkId = uuid();
const authorBookNode = db.get(linkId).put({
uuid: linkId,
type: "Link",
name: "author_book",
date: date,
});
authorBookNode.get("book").put(book);
authorBookNode.get("author").put(author);
book.get("authors").set(authorBookNode);
author.get("books").set(authorBookNode);
return authorBookNode;
}
Here are some of the queries that we can run after creating the nodes and the
relationships:
- Log the titles of the books authored by Author 1:
authorNodes[0].get("books").map().get("book").get("title").once(log);
- Log the author names of Book 1:
bookNodes[0].get("authors").map().get("author").get("name").once(log);
We can also combine queries from "book review" and return review results by
traversing the graph from an author. For example:
- Given an author, log the titles of the book they have authored, and any ratings associated with the books:
authorNodes[0].get("books").map().get("book").get("title").once(log);
authorNodes[0].get("books").map().get("book").get("reviews").map().get("rating").once(log);
Favorite Books
If you remember from the previous sections readers can create lists and add
their favorite books to them. The diagram below shows the nodes and the links
that we are going to create:
- The
book_listnode represents a list that contains a set of books added by the reader. - The
booksproperty inbook_listholds the reference to the set of books. - The
belongs_toproperty references the reader that created the list - The
favorite_booksproperty in thereadernode references a set that holds all thebook_listnode references.
Now, we can define a function that creates the nodes and links shown above:
function favoriteBooks(opt) {
const {db, reader, books, listName} = opt;
const listId = uuid();
const list = db.get(listId).put({
uuid: listId,
type: "Link",
name: "favorite_list",
list_name: listName,
});
const faveBooks = db.get(uuid());
for (book of books) {
faveBooks.set(book);
}
list.get("books").put(faveBooks);
list.get("belongs_to").put(reader);
reader.get("favorite_books").set(list);
return list;
}
And here are some of the queries that we can run after creating the nodes and
the relationships:
- Log all the favorite books for Reader 1 across all of their lists
readerNodes[0].get("favorite_books").map().get("books").map().get("title").once(log);
- Log the titles of the favorite books for Reader 1 in the "List 1" list
readerNodes[0].get("favorite_books").map().once(list => {
if(list.list_name === "List 1") {
db.get(list.books).map().get("title").once(log);
}
});
- Log the names of the private lists created by Reader 1
readerNodes[0].get("favorite_books").map().once(list => {
if(list.is_public === "false") {
log(list.list_name);
}
});
Publish Books
Publishing a book can be represented by a link node between a publisher and a
book. The diagram below shows the nodes and the relationships:
- The
publish_booknode is the link node that holds references to the published book and the publisher - The
bookproperty in thepublish_booknode references the published book. - The
publisherproperty in thepublish_booknode references the publisher. - The book node contains a property called
publication_detailsthat also references thepublish_booknode. - The publisher has a property called
booksthat is a set holding references to thepublish_booklink nodes.
Using the information above, we can create a function that creates the nodes and
the relationships:
function publishBook(opt) {
const {db, publisher, book, date} = opt;
const linkId = uuid();
const publishLink = db.get(linkId).put({
uuid: linkId,
type: "Link",
name: "publish_book",
date: date,
});
publishLink.get("book").put(book);
publishLink.get("publisher").put(publisher);
book.get("publication_details").put(publishLink);
publisher.get("books").set(publishLink);
return publishLink;
}
After creating the nodes and the relationships, we can then run the following
queries:
- Log the titles of the books published by Publisher 1
publisherNodes[0].get("books").map().get("book").get("title").once(log);
- Log the titles of the books published by Publisher 2
publisherNodes[1].get("books").map().get("book").get("title").once(log);
- Given Book 1, log the name of its publisher
bookNodes[0].get("publication_details").get("publisher").get("name").once(log);
Book Category
Categorizing books can be represented by link nodes between category nodes and
book nodes. The diagram below shows the nodes and links that we need to create:
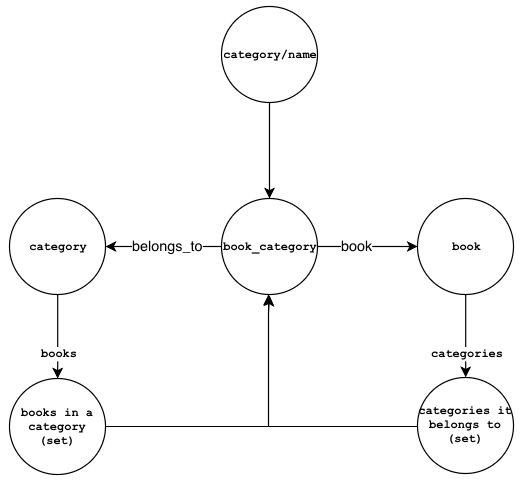
- The
book_categorylink node relates a category to a book. - The
belongs_toproperty in thebook_categorynode references the category. - The
bookproperty in thebook_categorynode references the book. - The
category/nameset holds references tobook_categorynodes. - The
booksproperty in thecategorynode is a set that holds references to thebook_categorylink nodes. - The
categoriesproperty in thebooknode is a set that also holds references to thebook_categorylink nodes.
Using the information above we can create a function that creates the nodes and
the links for categorizing a book:
function bookCategory(opt) {
const {db, category, book, categoryName} = opt;
const linkId = uuid();
const categoryLink = db.get(linkId).put({
uuid: linkId,
type: "Link",
name: "book_category",
category_name: categoryName,
});
categoryLink.get("book").put(book);
categoryLink.get("belongs_to").put(category);
db.get(`category/${categoryName}`).set(categoryLink);
book.get("categories").set(categoryLink);
category.get("books").set(categoryLink);
return categoryLink;
}
After creating the nodes and the relationships,
we can run the following queries:
- Log the titles of all the books in Category 1:
categoryNodes[0].get("books").map().get("book").get("title").once(log);
- Given a book, log the names of the categories it belongs to:
bookNodes[0].get("categories").map().get("belongs_to").get("name").once(log);
- Given the categories, log the titles of the book in Category 1:
db.get("category/Category 1").map().get("book").get("title").once(log);
User Roles
In order to assign roles to a user, we can create a set and add the role links
to the set. The diagram below shows the nodes and the links that we need to
create:
- The
rolenode link contains the role's information. Itsuserproperty references the user node and itsassigned_toproperty references a user type node. A user type node can be a reader, author, or publisher. - The
rolesproperty in theusernode is a set that holds references torolenodes. - The user type node has a
roleproperty that points to therolenode.
In addition to the nodes and the links above, we also want to create sets that
references all the roles, users, and different user types:
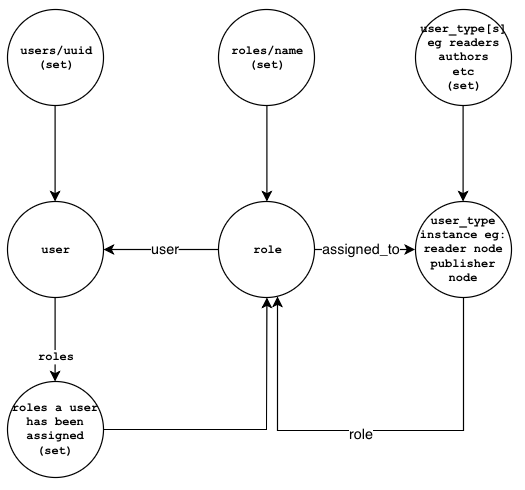
-
users/uuid: a set that holds references to users created. -
roles/name: a set that holds references to roles created. -
[user_types]: a set that holds references to user types created. For examplereaders,authors,publishers.
Using the information above we can define a function that creates the nodes and
links:
function userRole(opt) {
const {db, name, userTypeNode, user} = opt;
const linkId = uuid();
const roleLink = db.get(linkId).put({
uuid: linkId,
type: "Link",
name: "role",
role_name: name,
});
roleLink.get("user").put(user);
roleLink.get("assigned_to").put(userTypeNode);
db.get(`roles/${name}`).set(roleLink);
const userUuid = user._.put.uuid; // HACK, DONT DO THIS IN ACTUAL APP
const userType = userTypeNode._.put.type.toLowerCase() + "s"; // HACK, DONT DO THIS IN ACTUAL APP
db.get(`users/${userUuid}`).set(user);
db.get('users').set(user);
db.get(userType).set((userTypeNode));
user.get("roles").set(roleLink);
userTypeNode.get("role").put(roleLink);
return roleLink;
}
In the function above, lines A and B were used to avoid async callbacks
for demonstration purposes only. Always usegetto resolve data in Gun nodes.
After creating the nodes and the relationships, we can run the following
queries:
- Log the names of all the readers
db.get("readers").map().get("name").once(log);
- Log the emails of all the users
db.get("users").map().get("email").once(log);
- Log the roles of User 1:
userNodes[0].get("roles").map().get("role_name").once(log);
Follow People
The "follow" relationship is a little bit different than the relationships that
we we've covered so far. That's because most of the relationships above, like
authoring a book or reviewing a book, imply a bi-directional relationship. But
following is not necessarily bi-directional. For example, User A can follow User
B, but that doesn't imply that User B is also following User A immediately.
Because of that we are going to need to define two sets for each user to keep
track of the "followings" and the "followers". The diagram below demonstrates
the nodes and the links that we'll need to create when User A follows User B:
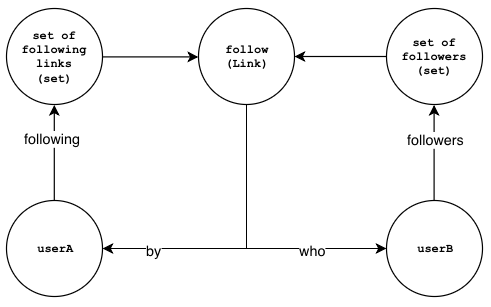
- The
followlink node represents a "follow" relationship betweenuserAanduserB. - The
whoproperty in thefollowlink node represents the "destination" of the "follow" relationship. - The
byproperty in thefollowlink node represents the "source" of the "follow" relationship. - The
followingproperty inuserAis a set holding link references tofollownodes. - The
followersproperty inuserBis a set holding link references tofollownodes.
Now, if UserB also follows UserA, we'll have the following relationships:
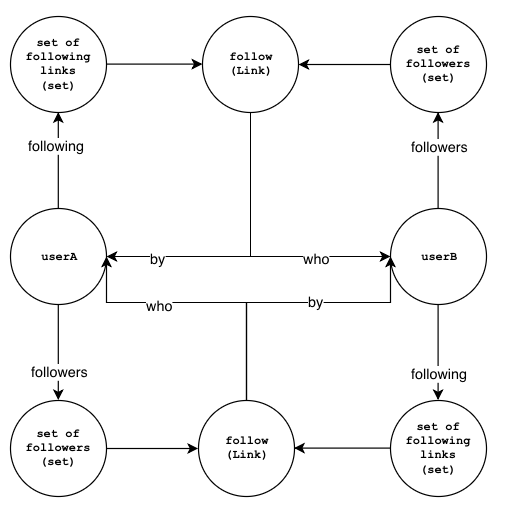
Now, using the information above, we can define a function that can link two
people given a source node (by), and a destination node (who):
function follow(opt) {
const {db, sourceNode, destinationNode} = opt;
const linkId = uuid();
const followLink = db.get(linkId).put({
uuid: linkId,
type: "Link",
name: "follow",
date: new Date().toISOString(),
});
followLink.get("who").put(destinationNode);
followLink.get("by").put(sourceNode);
sourceNode.get("following").set(followLink);
destinationNode.get("followers").set(followLink);
return followLink;
}
After creating the nodes and the relationships we can run the following queries:
- Log the name of all the people that Reader 2 follows
readerNodes[1].get("following").map().get("who").get("name").once(log);
- Log the name of all the people that are following Reader 2
readerNodes[1].get("followers").map().get("by").get("name").once(log);
Holistic Queries
Now that we have created some data and added some relationships, let's ask the
following holistic question:
- What is the most popular book?
For the sake of simplicity we are going to define a popular book as one that has
been included in many favorite lists by readers, and also has five star rating.
Using the promise helpers (included in the article's repo) we can run two
queries, one on the favorite lists, and the other on 5-star reviews:
// uuids of the books included in all favorite lists
q(db).get("readers").getSet()
.get("favorite_books").getSet()
.get("books").getSet().get("uuid")
.data();
// uuids of the 5-star books
q(db).get("reviews/5").getSet()
.get("book")
.get("uuid")
.data();
Then we can count the number of books that have been included in the favorite
lists, and sort them in descending order. The first book will be the book with
the highest number of inclusion. Then we can simply check if that book is
included in the 5-star list. You can see the full code snippet in the main.js
file.
You can use the example above an run all kinds of queries to gain interesting
insights into your data. The idea is to first run some queries to collect the
uuids of interest. Once you have them, it's just a matter of doing some basic
comparison to get to the answer that you're looking for.
Further Improvements
There are a couple of things that you should consider to improve the
implementation:
- Using schema validation to enforce a structure before saving data. There is an extension called gun-schema that uses
is-my-json-validpackage behind the scenes to help you validate your object shapes. - Creating scopes for your data. There is an extension called Reticle that helps you create scopes to avoid collisions between keys.
- Validating constraints before adding to the database is important if you want to make sure unexpected data is not added. In addition, you may also want to check uniquness if a relationship requires it.
- Using GraphQL is one way of establishing a data protocol between clients and a system's backend. Using GraphQL the clients can ask what they need and not worry about the details of the backend. You may want to look at the Graphql-gun package which is a graphql API for GunDB.
And please join the GunDB chat room if you have any questions or if you are not sure about something, everyone is very friendly and helpful.
Conclusion
I hope that this article gave you some ideas on how to go about data modeling
with GunDB. In this article I only scratched the surface of what's possible with
GunDB. By no means is this a comprehensive model of the entire system. Data
modeling, just like any design process, involves a good amount of planning and
experimentation. A good and well-thought design however, can save you a lot of
time and effort down the road. If you have any thoughts on how to improve the
models presented in this article, please leave a comment, any input is much
appreciated.
Appendix 1: Draw.io
My favorite diagramming tool is Draw.io available at https://draw.io. It has all
the features that you would expect from a diagramming tool.
I'm going to show you my favorite feature of Draw.io. This feature enables you
to automatically convert descriptions to diagram. It's my favorite feature
because I can describe models and relationships with plain text and visualize
them very quickly. In addition to that, I can track the changes to text in Git
over time and see what has changed. I wouldn't be able to do that otherwise if
everything was documented only by PDFs or images.
You can define a node and its properties using the following format:
node name
- property
- property2
--
* ref
* ref 2
Then, you can create a diagram from the description above by going to Arrange >
Insert > From Text. A small window will open. At the bottom pick "List" from the
dropdown and copy paste the example above and click insert. You can see the
result in the figure below:

You can use the same method for creating graphs. But instead of choosing "List"
from the dropdown, you will need to choose the "Diagram" option. Below is a
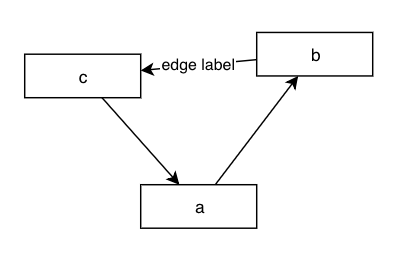
simple example describing the format that Draw.io accepts:
;GraphName:
a->b
b->edge label->c
c->a
The snippet above creates the following diagram: